《Web 3.0 应用架构》解读
本文大量内容摘自Preethi Kasireddy的《The Architecture of a Web 3.0 application》一文,并添加了我的解读。
感兴趣的同学可以去阅读原文:
https://www.preethikasireddy.com/post/the-architecture-of-a-web-3-0-application
在讲Web 3.0应用架构之前,我们需要先了解一下Web 2.0。
Web 2.0 应用架构
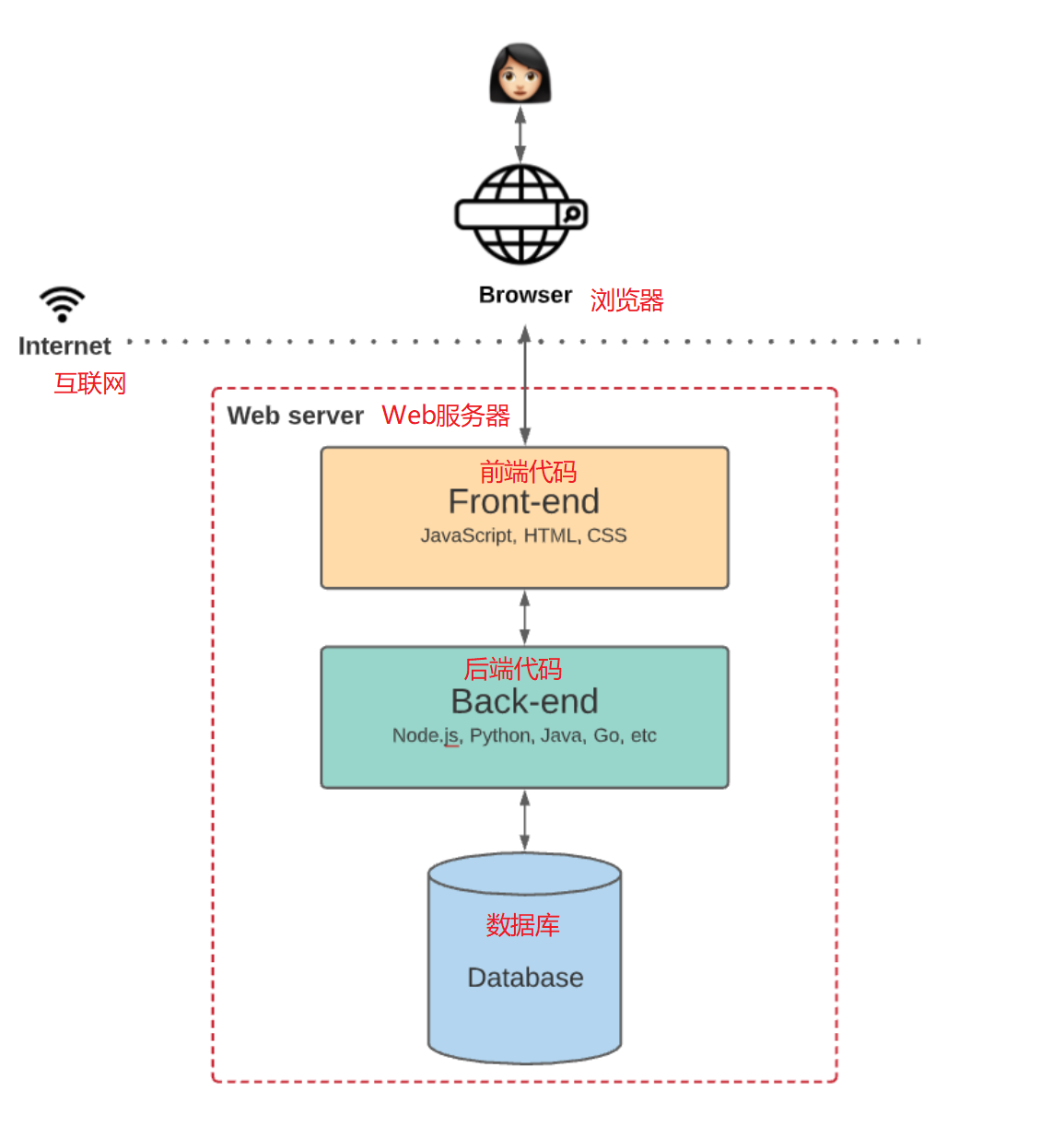
一个典型的Web 2.0应用,例如一个博客应用,通常包含3个部分:
数据存储系统
这个系统用于存储博客应用的重要数据,例如用户、文章、标签、评论等等,构成了一个数据持续更新的数据库。
后端代码
后端代码用于定义博客应用的业务逻辑,例如注册用户,发表文章,发布评论等等。
前端代码
前端代码则是博客应用的用户界面(UI)逻辑,包括博客的外在表现,以及如何与用户进行交互。
总结一下,我们使用一个博客应用时,我们与它的前端代码进行交互,然后前端代码再与后端代码交互,而后端再与数据库进行交互。
博客应用的这些代码被部署在中心化的服务器上,然后其他用户通过浏览器来访问。
但是,区块链技术为Web3.0解锁了一个全新的方向。
Web 3.0 有何不同?
Web 2.0 的应用需要部署在中心化的服务器上。以博客为例,原文举的例子是Meidum,例如新浪博客(或者其他程序员们熟悉的各种技术博客),或者微信朋友圈,QQ空间等,他们所部署的服务器,都属于某个实体公司或者组织,如新浪或者腾讯,这就是所谓的中心化服务器。
而Web 3.0消除了这个中间人的必要性,不再需要中心化数据库来存储应用的数据和状态,也不需要中心化的Web服务器来运行前端和后端代码。
取而代之,我们可以使用区块链技术,在由无数匿名节点组成的非中心化状态机上,搭建各种应用。
这里的状态机,指的是用于维护程序状态和状态变化规则的机器。区块链,就是由这样的状态机组成的。
这些状态机,由网络上的所有人一起共同维护,不属于任何一个实体,所以是非中心化的。
Web 3.0的后端代码,也就是应用的业务逻辑,通过编写智能合约(Smart Contract),然后部署到这些非中心化的状态机上来实现。任何人都可以写一个区块链应用然后部署到这些共享的非中心化状态机上。
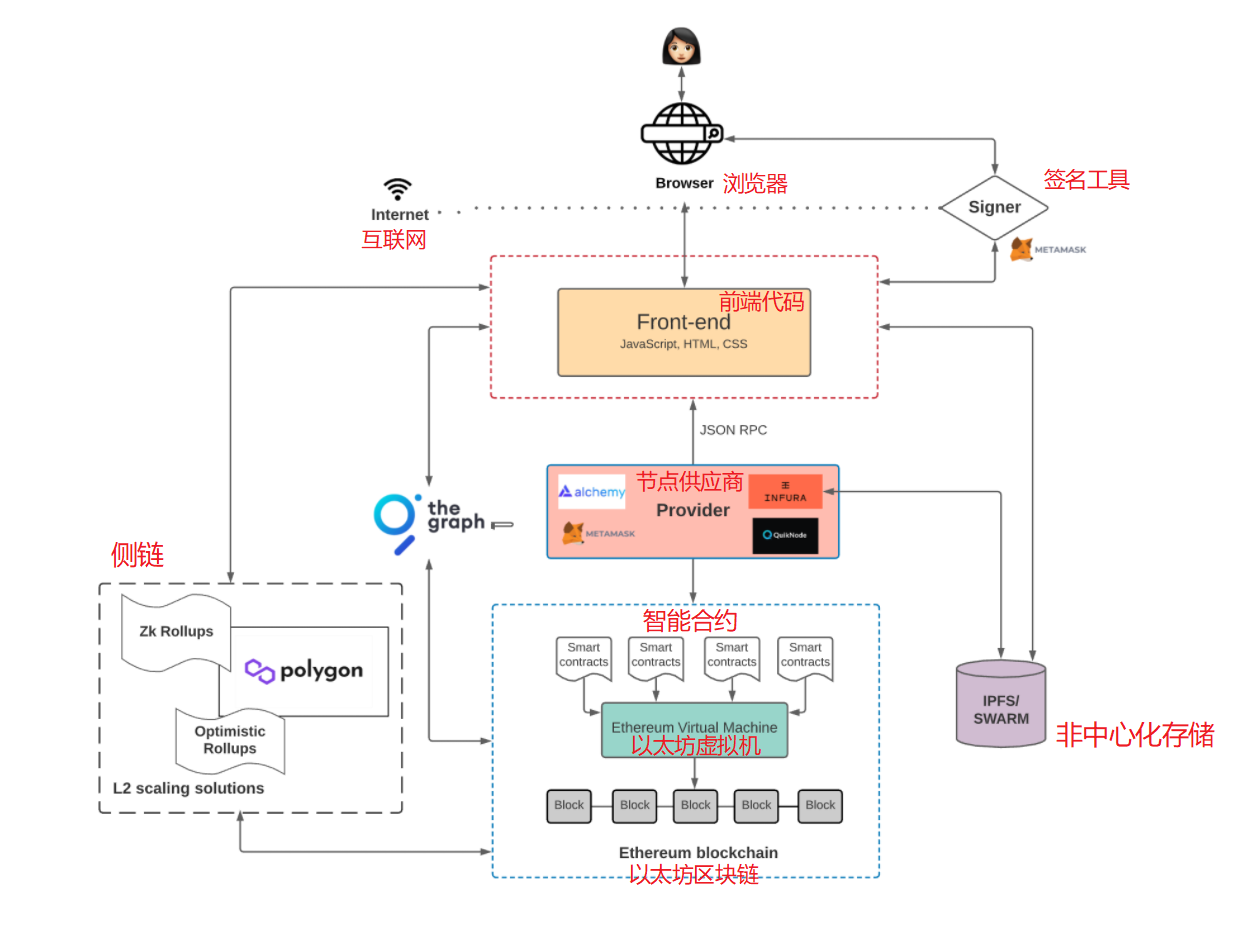
所以,先不考虑前端代码的情况下,Web 3.0应用的架构就变成这样子:
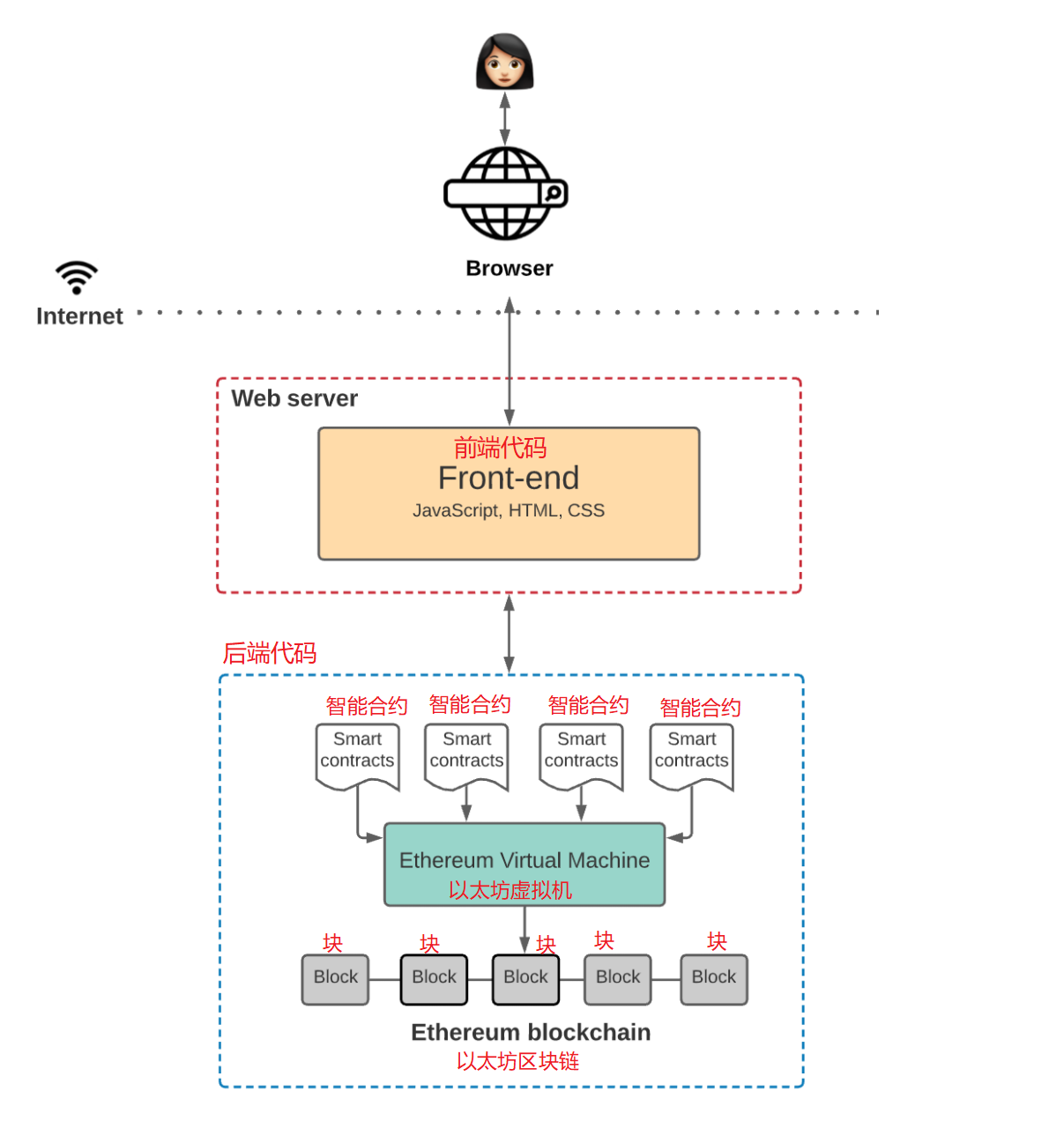
所以 Web 3.0应用架构中包含:
区块链
以太坊区块链,经常被称为“世界计算机”,因为它可以一个可以被全世界所访问,由无数节点组成并共同维护的状态机。
它被设计为可以被任何人访问和编写,于是,也就无法被任何人所拥有,而只能共同拥有。
另外,一条很重要的规则是,区块链上的数据无法被修改,只能被增加。也就是说,我们只能往区块链上增加数据,而不能删除或者修改原数据。
智能合约
智能合约是运行在区块链上的代码,它定义了区块链上状态变化的逻辑。这些代码通常使用高级语言编写,例如Solidity或者Vyper。
这些代码存储在区块链上,可以被任何人访问和审查。
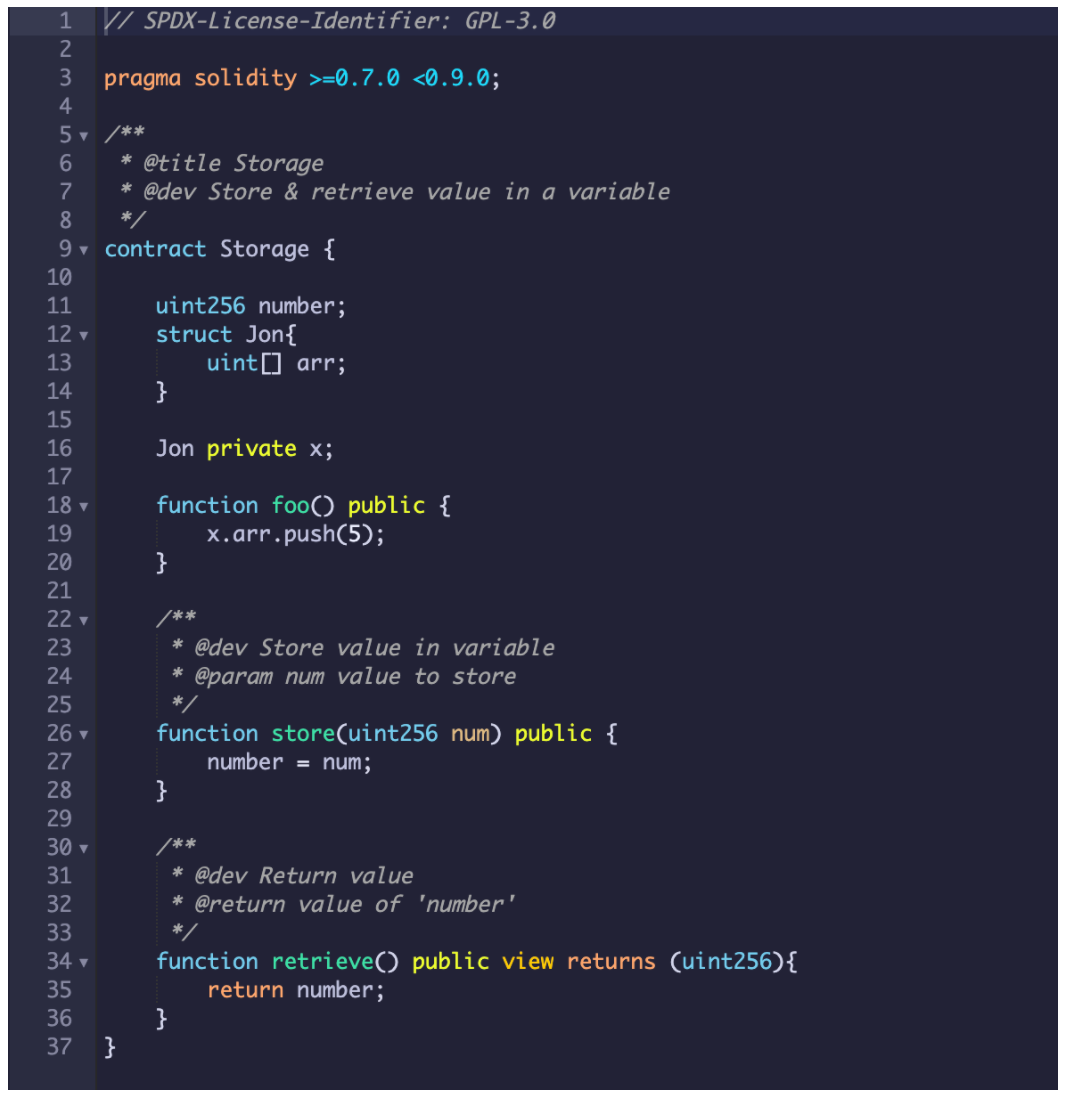
示例
以太坊虚拟机
以太坊虚拟机用来执行智能合约的代码。智能合约需要被编译成字节码才能在以太坊虚拟机上运行。
前端代码
Web 3.0的前端代码负责用户交互,并与通过智能合约定义的业务逻辑进行交互。
但是真实情况是,这部分要比图上画的要复杂的多。
前端代码如何与以太坊网络上的智能合约进行交互?
注意,可能是由于以太坊作为是区块链的一个典型代表,所以,原文从这里开始经常把以太坊和区块链经常混着用。
在以太坊的网络上,任何一个节点都包含以太坊状态机的所有状态,包括代码,以及所有智能合约的相关数据。任何事务在虚拟机上的执行请求,都会被广播到网络中的其他节点中。
所以,当我们想要访问区块链上的数据时,我们需要与其中任意一个节点进行交互。然后一个所谓的“矿工”会负责执行我们的请求,并把最终状态传播到整个网络上。
广播一个新事务请求有两种方式:
- 1). 自己搭建一个运行以太坊区块链软件的节点
- 2). 使用第三方服务,例如 Infura, Alchemy, 或者 QuickNode。
使用第三方是更经济的方式,因为自己搭建以太坊节点需要花费很多天的时间,因为有大量的数据需要同步,而且这些数据会越来越多。
这些第三方服务,被称为节点供应商 Provider。
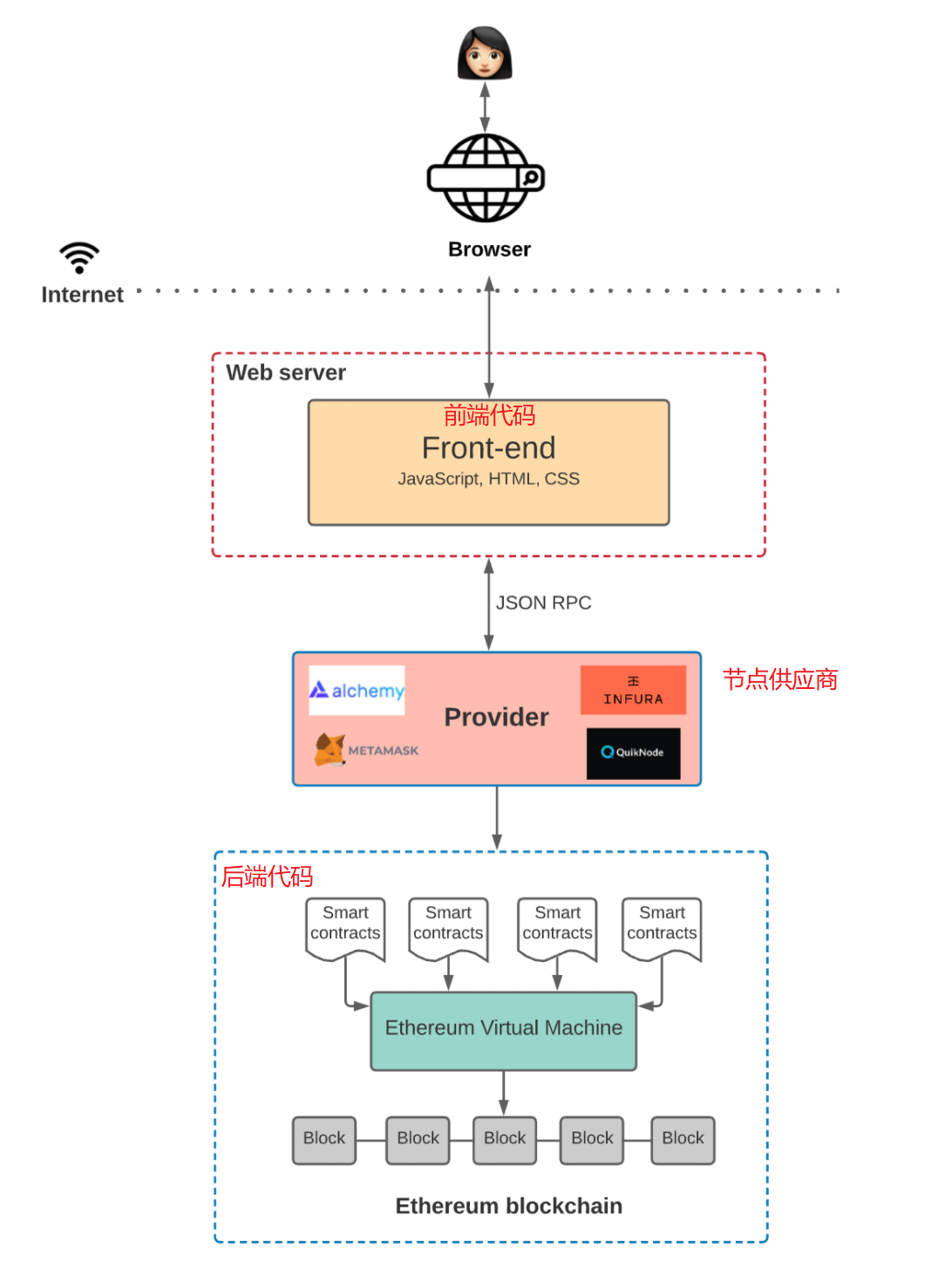
所有的以太坊客户端都通过JSON-RPC这种统一方式来进行交换数据。
一旦我们通过节点供应商连接到上了区块链网络,我们就可以访问区块链上的所有数据了。
但是,如果想要往区块链上写入状态,在向区块链提交这个事务之前,则还需要做一件事:用你的私钥对这个事务进行签名。
以区块链博客应用为例,用户通常可以随意浏览博客文章,但是,如果想要发布新文章,则需要对这个发布文章的事务进行签名,否则这个事务将不被受理。
对事务进行签名,就是Metamask这个工具做的工作:签名工具。
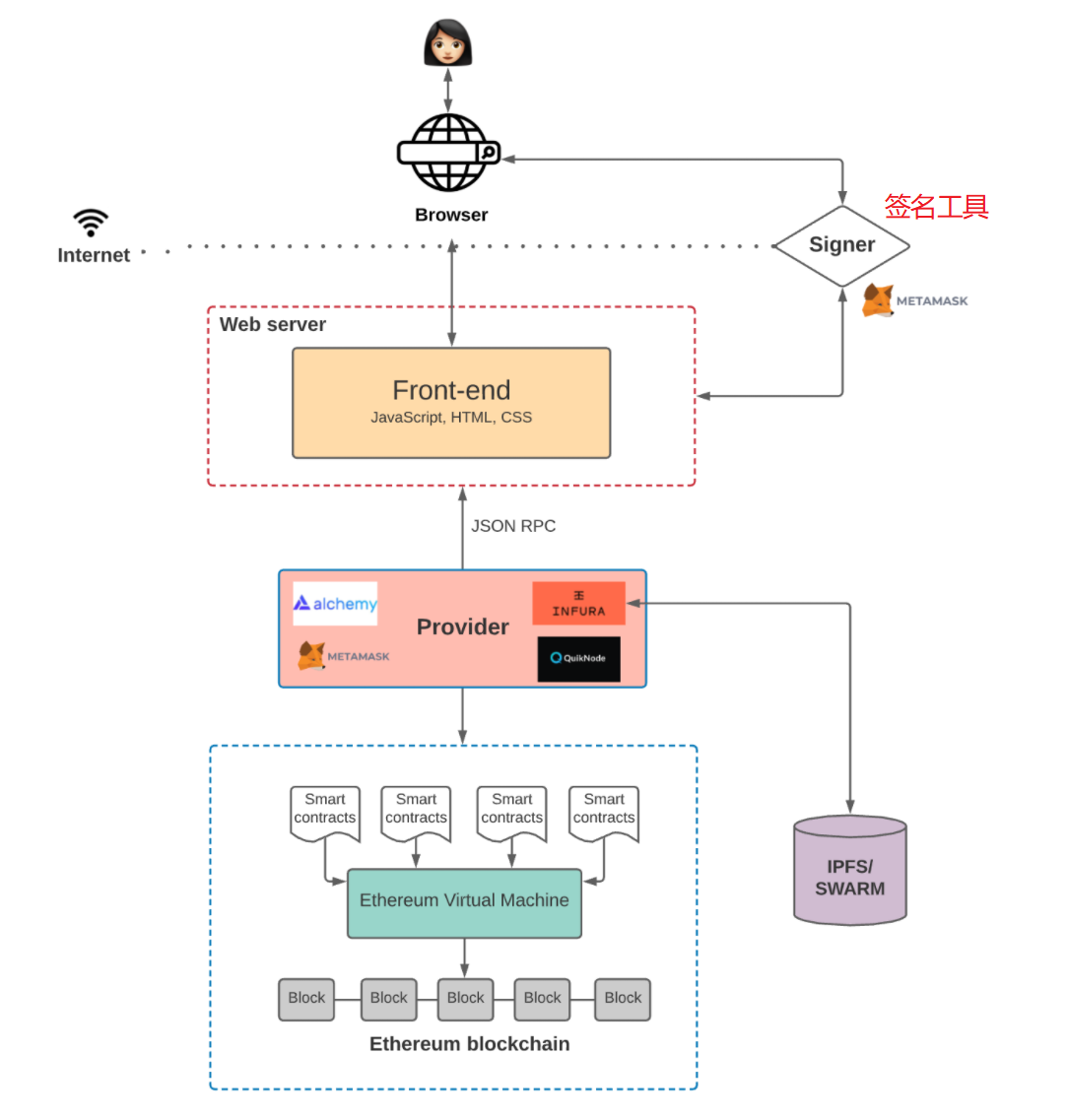
在这个图中,前端代码还没有被存储在区块链中,它依然可以像以前一样,部署在亚马逊的AWS或者阿里云上,但是,这样就不能成为一个彻底的非中心化应用。
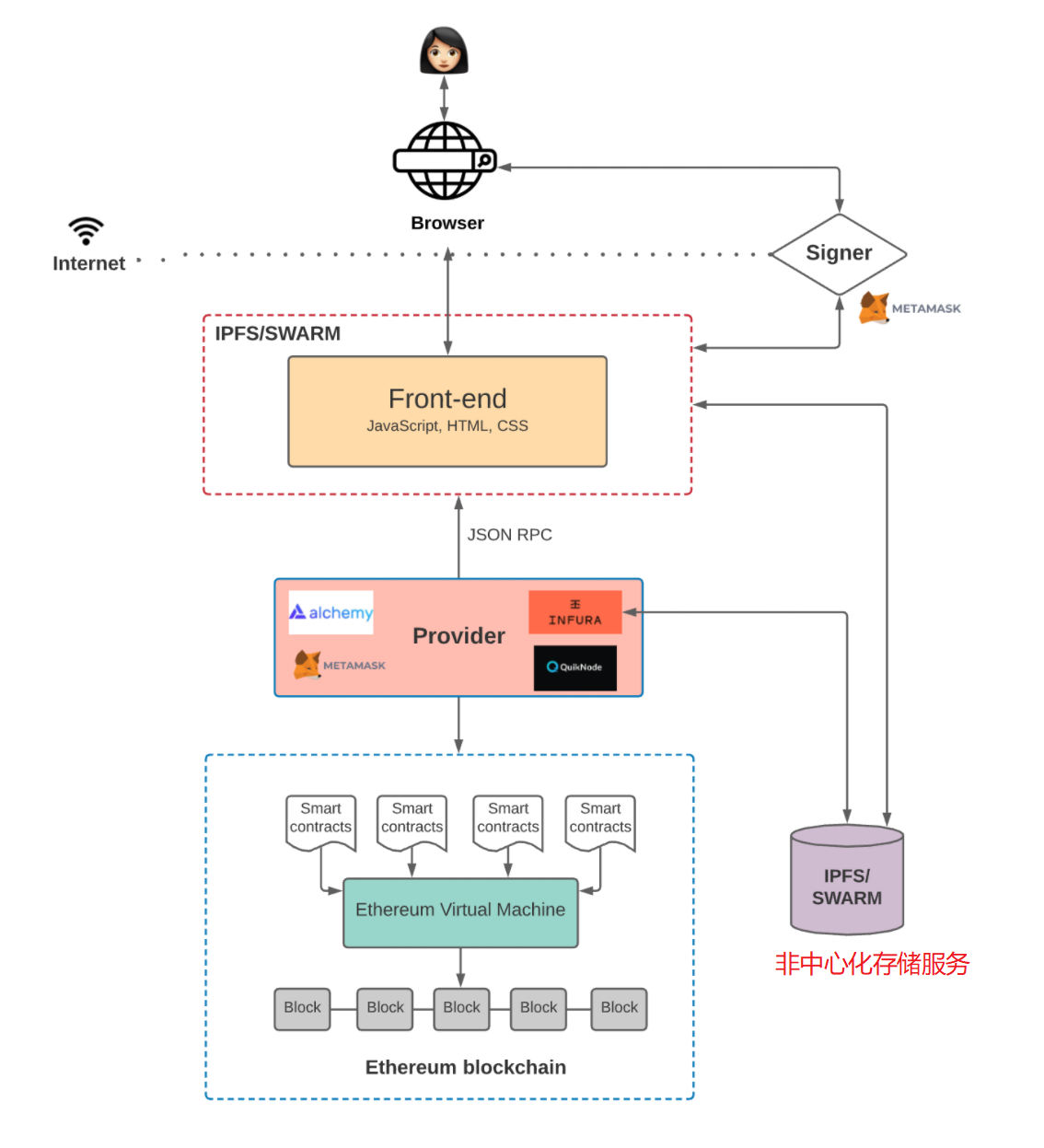
所以,还需要一个非中心化的存储方案,例如IPFS 或者 Swarm。
现在,我们的非中心化软件架构变成了这样:
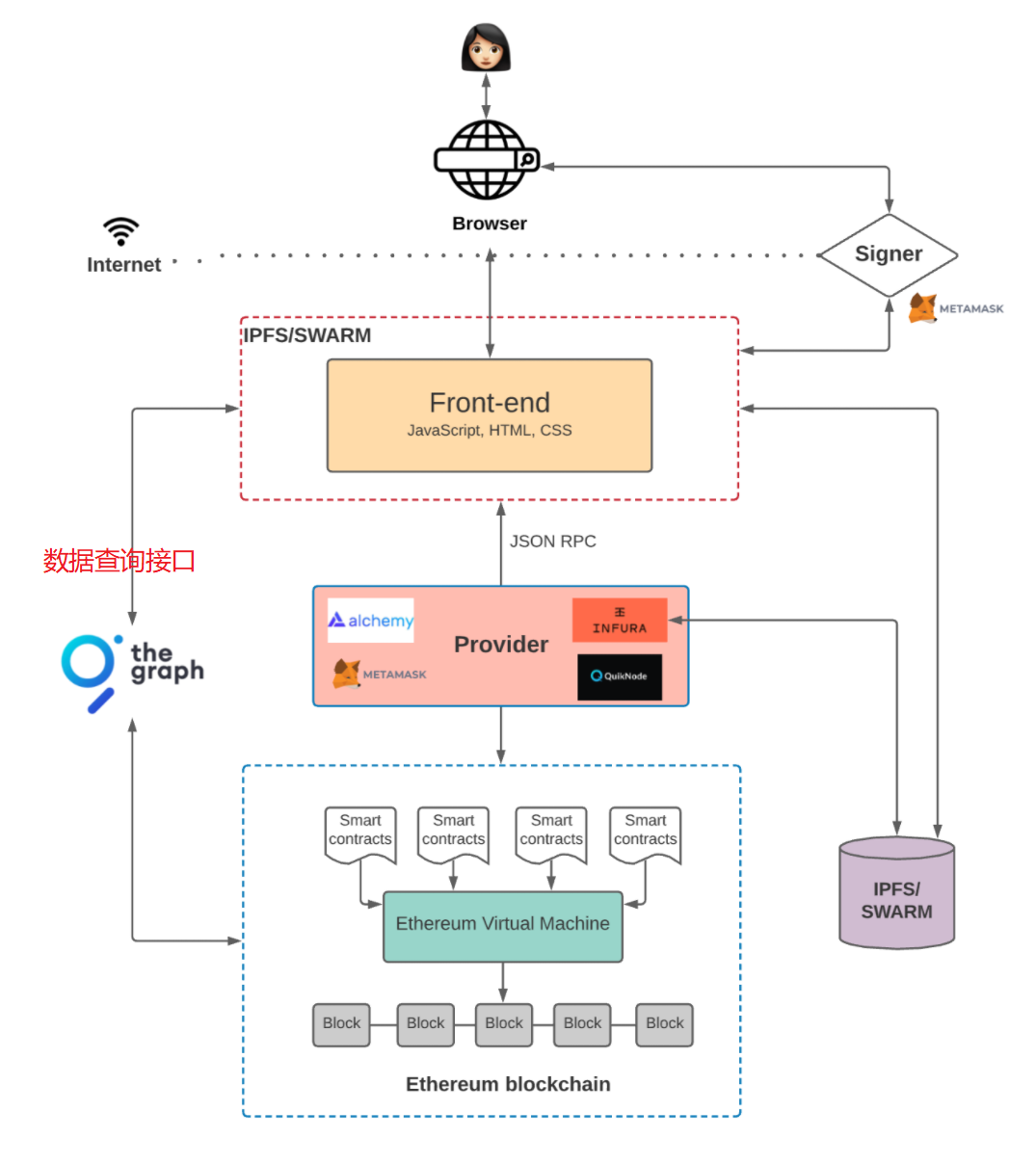
区块链数据查询
讲完如何通过智能合约向区块链写数据,那么该如何查询智能合约的数据呢?有两种主流方式:
智能合约事件
我们可以监听智能合约的事件。通过在智能合约代码中编写相应的事件发布逻辑,前端代码可以获取到对应的事件,并进行相应处理。
这种方法有个很大的缺陷:由于区块链不允许修改数据,包括智能合约代码,一旦智能合约被部署,如果想补充新的事件,就只能重新部署一个新智能合约,并重新监听。
The Graph 图查询接口
The Graph 图查询接口,是一种为了方便查询区块链数据的离链索引方案。我们可以定义需要索引的智能合约,相关的事件,以及如何进行数据转换。通过这种方式,区块链的数据就被索引起来,然后再通过GraphQL语言来进行查询。
规模化非中心化应用
在以太坊网络上构建非中心化应用,需要花费大量的费用成本,而且体验很差(主要指要将数据同步到所有的节点需要花费比较长的时间)。
一个比较流行的方案是Ploygon,L2 规模化方案。这种方案通过在“侧链”而非主链上执行事务,然后定期将状态同步到主链,从而大大降低了成本提高了速度。
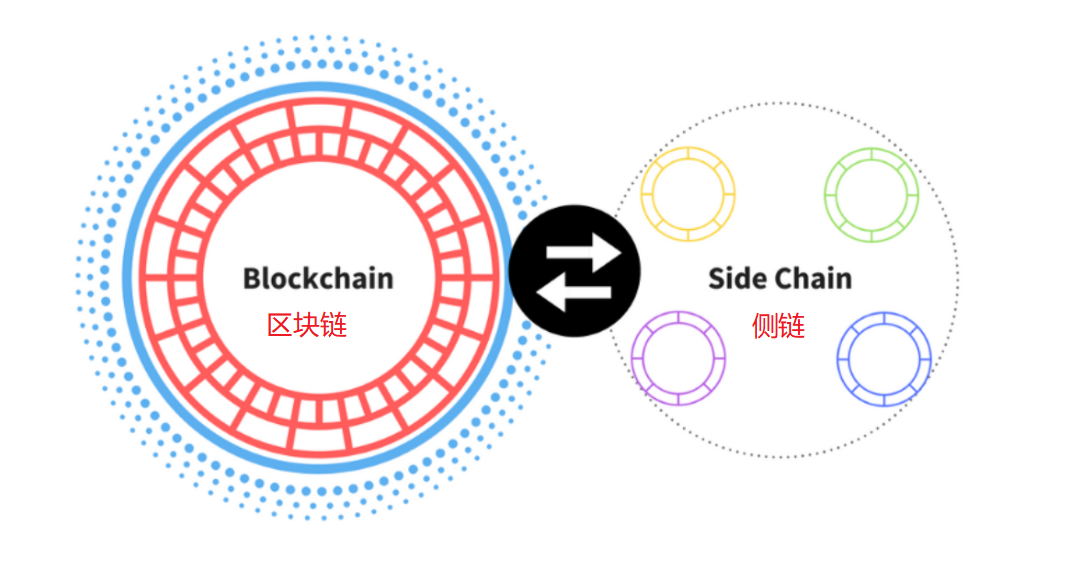
类似的方案还有 Optimistic Rollups和zkRollups。
现在,我们的架构变成了这样子:
集成方案
为了降低非中心化应用的开发难度,一些开发框架正在被开发出来。例如,Hardhat就是一个方便以太坊开发者创建、部署和测试智能合约的框架。通过Hardhat的网络,开发者甚至可以把智能合约部署在本地而不需要部署到线上环境。它还提供了插件系统和其他工具等来提升开发体验。
以上。
个人总结
本文中,我特意将两个词做了个人倾向的翻译:
- decentralize: 翻译为“非中心化”而不是通常的“去中心化”
- transaction:翻译“事务”而非“交易”
希望可以更冷静地看待当前的区块链、Web3.0以及元宇宙的相关技术。
技术只是工具,可以用来造福社会,也可以用来割韭菜。
